Vejce vejci – hledání podobných dokumentů a plagiátů
- 1.Jak se odhalují podobnosti textu (podezření na plagiát) v IS PCU?Obsah souborů v datovém úložišti IS PCU, u kterých je k dispozici čistě textová verze, je průběžně strojově analyzován. Každý dokument (závěrečná práce, seminární práce, esej, prezentace, ...), který si uživatel v systému vyhledá, lze porovnat a zobrazit k němu zdroje, které mají podobný text:
- klikněte na řádek se souborem (kliknutí pravým tlačítkem myši vyvolá panel podrobností vpravo, kliknutí levým tlačítkem vyvolá kontextové menu),
- použijte operaci „Vyhledat podobné dokumenty“ (ikona dvou vajíček „podobných jako vejce vejci“),
- využijte zobrazené podobnosti (či upravte nastavení a nechejte si podobnosti přepočítat) k tomu, abyste mohli posoudit, jestli se může jednat o plagiát, nebo nikoliv.
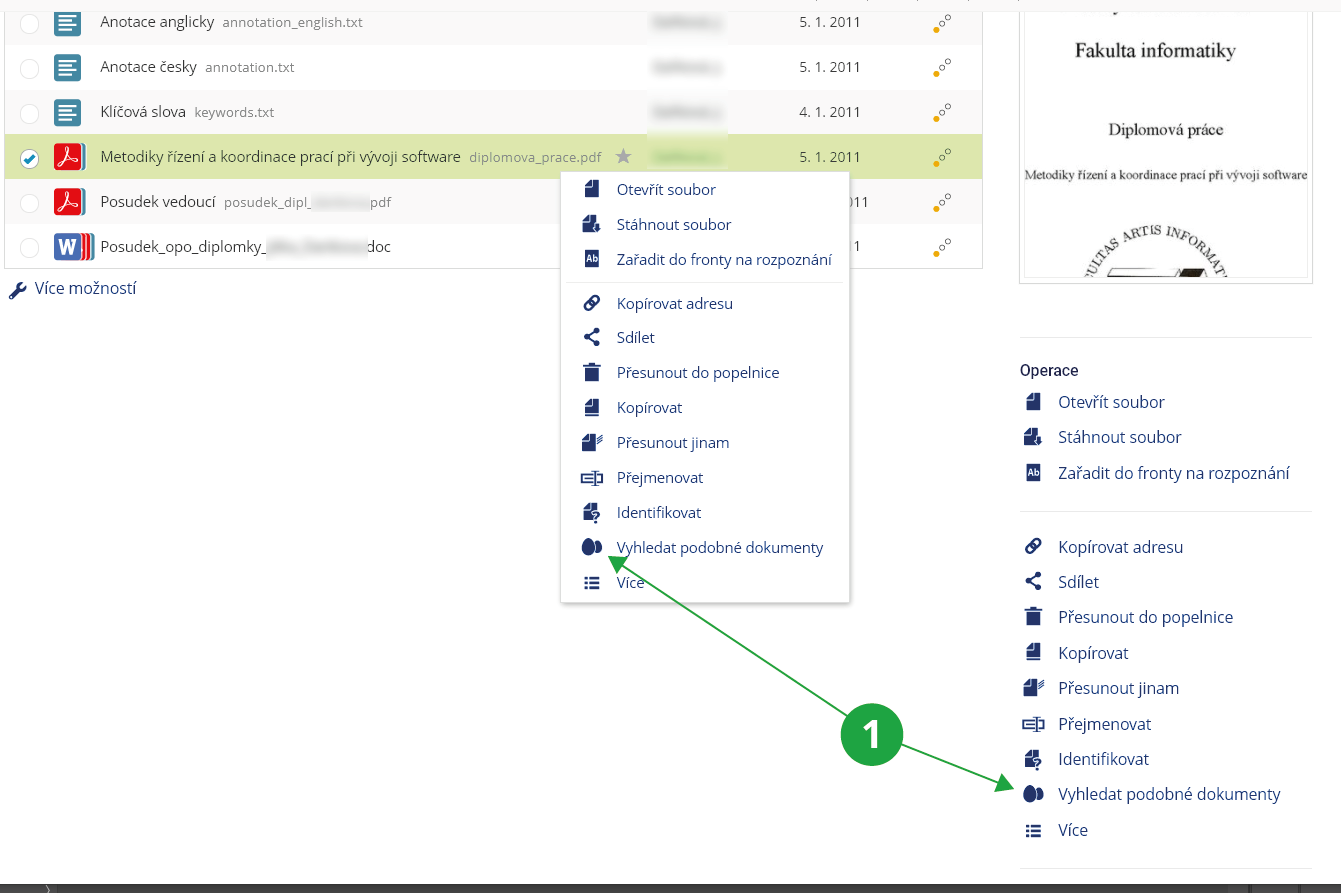
1 Operace „Vyhledat podobné dokumenty“.
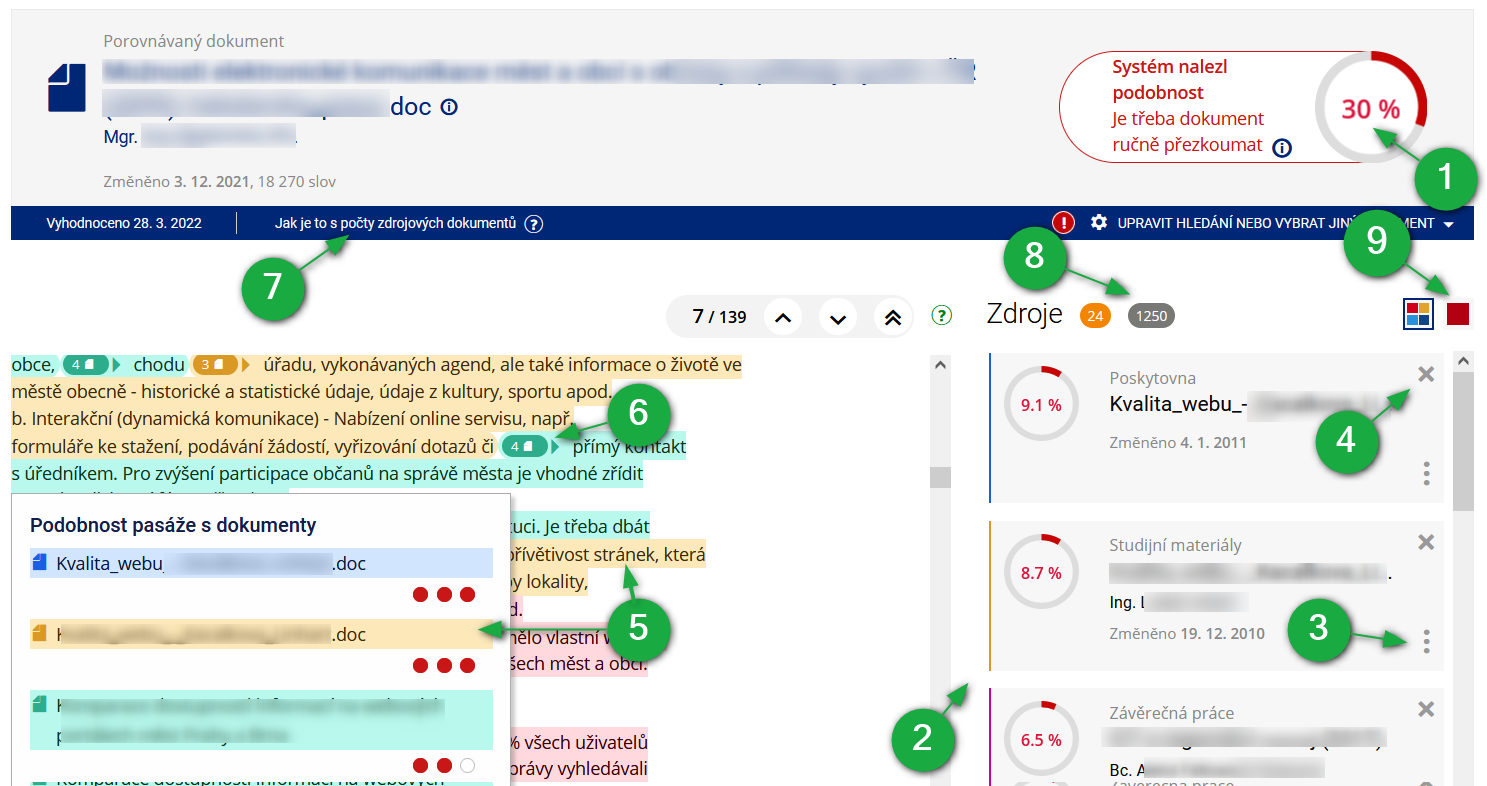
1 Procento celkové podobnosti s dokumenty v databázi a zdroji z internetu.
2 Seznam zdrojových dokumentů, se kterými je dokument podobný. U každého je zobrazeno procento podobnosti.
3 U každého zdrojového dokumentu je menu pod ikonou tří teček, kde lze o dokumentu zjistit více informací.
4 Za pomoci křížku lze odstranit z výpočtu zdrojový dokument, který není pro porovnání podobností relevantní (například z něj měl student čerpat a má jej řádně citovaný).
5 Po kliknutí na vybranou zvýrazněnou podobnou pasáž se zobrazí dokumenty, se kterými je text podobný.
6 Číslo v oválu označuje počet dokumentů, se kterými je následující pasáž podobná.
7 Po kliknutí se přehledně zobrazí počty zobrazených, přeskočených i vyřazených dokumentů včetně vysvětlení.
8 Ovály s čísly udržují přehled o zdrojových dokumentech. Přeskočené dokumenty lze zobrazit, vyřazené dokumenty obnovit.
9 Možnost přepnutí na jednobarevnou verzi zobrazení podobností, kdy je míra podobnosti vyjádřena intenzitou barvy.
Pro získání lepšího přehledu o míře nalezených podobností si lze zapnout jednobarevné zobrazení podobných pasáží, kdy je míra podobnosti vyjádřena intenzitou červené barvy.
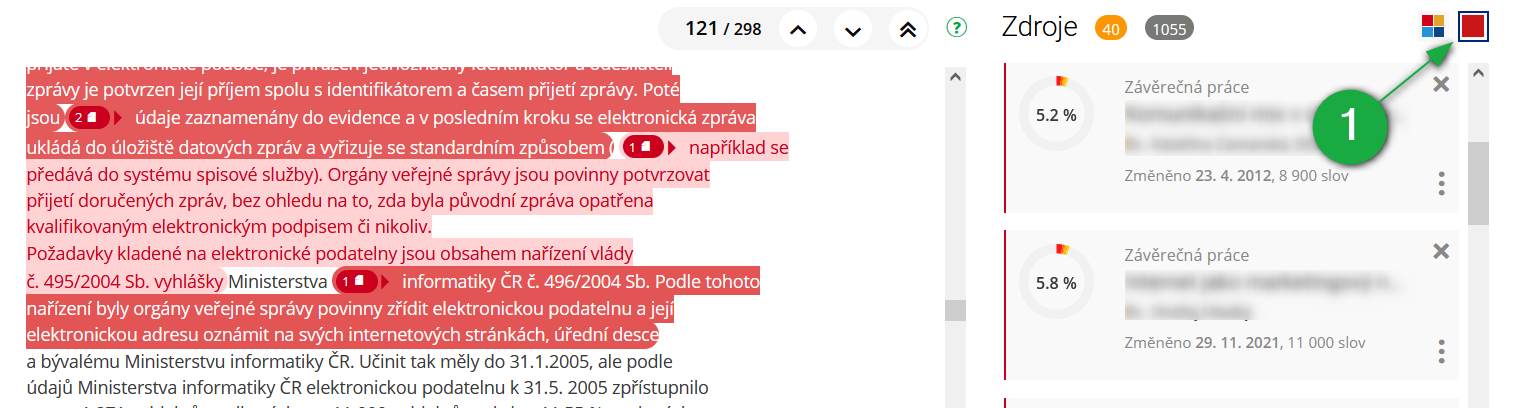
1 Ikonka pro přepnutí do jednobarevné verze zobrazení podobných pasáží.
- 2.Mezi jakými pracemi se podobnosti porovnávají?
Systém vyhledává podobnosti napříč sdílenou databází porovnávaných dokumentů, která zahrnuje vedle dokumentového serveru IS PCU i závěrečné práce zapojených škol v systému Theses.cz, seminární a jiné práce v systému Odevzdej.cz, vědecké publikace v systému Repozitar.cz a další dokumenty v informačních systémech provozovaných MU.
Protože je výrazné množství prací a dokumentů neveřejných, prohledávání společné databáze je efektivním nástrojem pro vyhledávání možných plagiátů. Student nemůže jen tak odevzdat seminární práci svého kamaráda z jiné školy, protože je vysoká pravděpodobnost, že již v systému je a našly by se s ní podobnosti. Zadání témat seminárních a závěrečných prací se často opakuje, a je tedy pravděpodobné, že systém již bude vědět o zdrojových dokumentech, ze kterých se pro toto téma obvykle čerpá. Součástí vyhledávání podobností je také algoritmus, který porovnávaný dokument analyzuje a zkoumá vůči zdrojům z internetu. Tento postup má různá technická omezení a je výpočetně a časově náročnější. Proto je přednostně používán pro archivy závěrečných prací. Seminární práce v odevzdávárnách a dlouhé odpovědi v odpovědnících jsou kvůli rychlosti zpracování primárně porovnávány vůči sdílené databázi všech zdrojových dokumentů. Ta zahrnuje mj. i zdroje z internetu někdy v minulosti dohledané pro účely kontroly některé z milionů porovnávaných závěrečných prací. Určitý rozdíl mezi vyhledáváním podobností k seminárním pracím (pro které je používána ona sdílená databáze zdrojů) a závěrečným pracím (k nimž je sdílená databáze zdrojů obohacena o nově stažené zdroje z internetu) tu nicméně je. Není se ale třeba obávat, databáze je opravdu rozsáhlá, díky čemuž ve většině případů systém „zná“ dostatek zdrojů, ze kterých studenti obvykle čerpají, a také dostatek zdrojů, ze kterých obvykle studenti opisují.Soubory uložené v Úschovně nebo Mém webu se zahrnou do vyhledávání podobností pouze v případě, že se jedná o vlastní Úschovnu nebo Můj web. Ostatním uživatelům se podobnosti nalezené v těchto úložištích nezobrazí.
- 3.Chci prověřit originalitu závěrečné práceVedoucí práce, který zpravidla chce prověřit kvalitu práce při psaní posudku, postupuje pomocíInformační systém Školitel (vybraný student) Archiv závěrečné prácea zvolí „Vyhledat podobné dokumenty“. Uvidí celkové procento podobností a vyznačené podobnosti, které může pomocí šipek postupně projít a posoudit, zda jsou úseky řádně citovány.
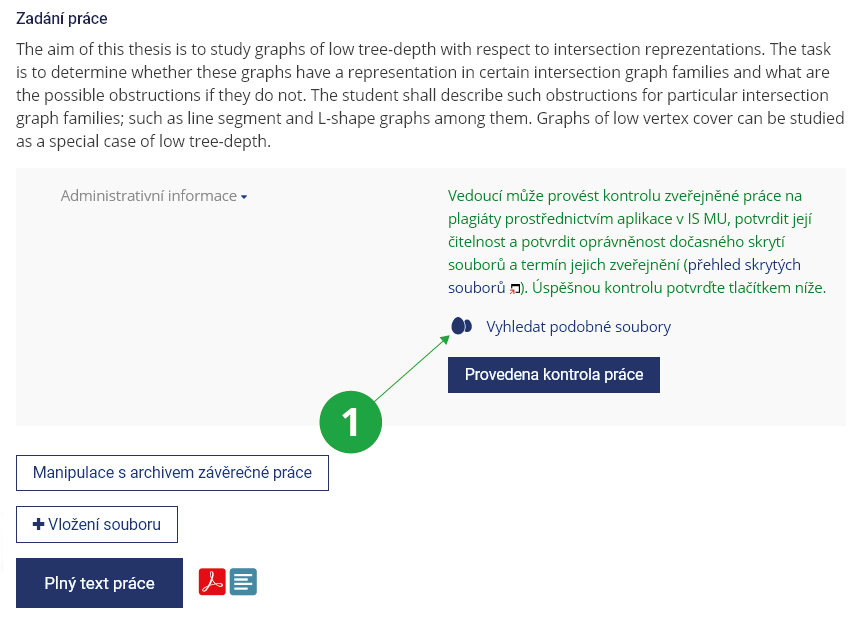
1 Předtím, než vedoucí práce potvrdí, že byla provedena kontrola práce, by měl použít funkci „Vyhledat podobné dokumenty“ a posoudit případnou shodu.
Je na čtenáři, aby posoudil význam nalezených podobností, tj. zda například student korektně cituje. Originalitu závěrečné práce nejlépe posoudí vedoucí práce (je nejvíce obeznámen s publikacemi v oboru).
- 4.Potřebuji dokument porovnat s neveřejným dokumentemPokud máte dokument v podobě, z níž lze vytvořit textovou verzi (není to tedy např. obrázek), vložte jej kamkoliv do IS PCU (např. do Poskytovny, do Studijních materiálů předmětu nebo do Mého webu) a IS PCU jej do mechanismu vyhledání podobností zahrne. Standardně se dokumenty od stejného vkladatele neporovnávají. Je tedy potřeba rozkliknout možnost „Upravit hledání nebo vybrat jiný dokument“, zvolit volbu „zahrnout dokumenty stejného vkladatele“ a zobrazit:
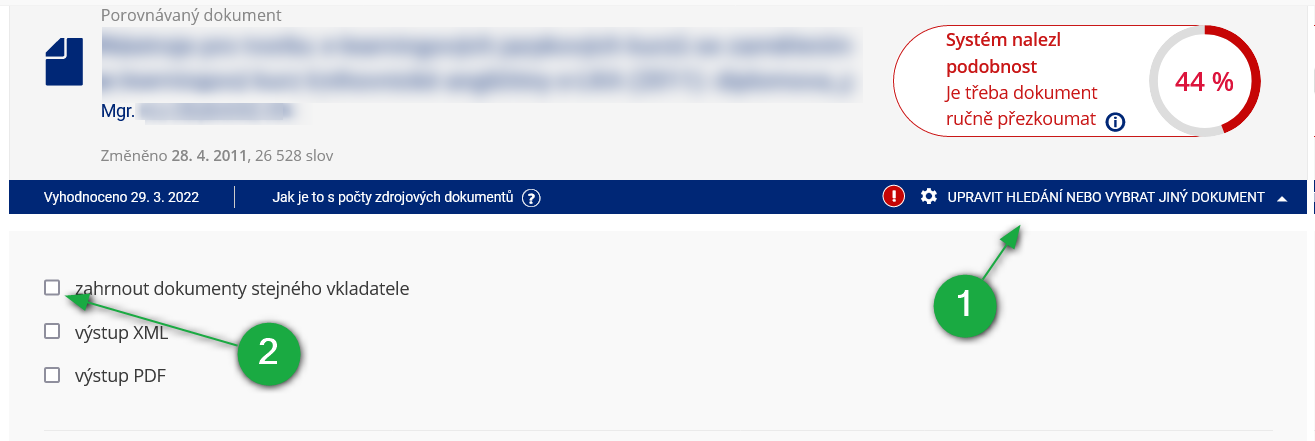
1 Kliknutím zde zobrazíte nastavení dalších parametrů hledání.
2 Pro porovnávání i mezi Vašimi vlastními dokumenty zaškrtněte volbu „zahrnout dokumenty stejného vkladatele“.
- 5.Jak funguje vyhledávací algoritmus?
Jedná se o porovnávání dokumentů mezi sebou:
- U každého dokumentu v databázi se generuje textová prohledávatelná verze. Algoritmus se v této textové verzi zaměřuje na podobné nebo parafrázované úseky textů a vyhodnocuje míru shody napříč celou sdílenou databází dokumentů, včetně zdrojů z internetu.
- Srovnávají se texty v češtině, angličtině a slovenštině, podmínkou je, aby měly alespoň pár vět či odstavců (v úplně malých souborech není dostatek textu pro jejich analýzy a nalezení podobností).
- Předtím, než se výsledek prezentuje uživateli, jsou vynechány ty dokumenty, které se překrývají jen v pasážích, jež jsou stejné jako u dříve nalezených zdrojů. Prakticky jde například o citace určitého zákona v další stovce závěrečných pracích a dokumentů na internetu. Pokud je podobných zdrojů méně než 10, zobrazí se pro přehlednost všechny bez vynechávání.
- Uživateli se zobrazí ty nejvíce relevantní dokumenty, u kterých dochází k významné podobnosti s hledaným dokumentem, a procento míry této podobnosti.
Pokud od sebe budou studenti vzájemně opisovat, systém vyhodnotí jejich odpovědi jako podobné a zobrazí procento podobnosti. Více na toto téma naleznete v otázce Mezi jakými pracemi se podobnosti porovnávají?
Jako varovný mechanismus pro studenty je důležité, že odevzdané práce jsou v IS PCU archivovány a mohou být podrobeny zkoumání opakovaně. Například kdykoliv později další vylepšenou verzí algoritmu. Nezapomeňte, že čas ušetřený opisováním může jednou znamenat mnoho práce navíc s napravováním vlastní reputace. Vývojáři IS PCU postupně algoritmus vylepšují a databáze prohledávaných dokumentů se neustále rozšiřuje o další zdroje. Co dnes systémy neodhalí, neznamená, že neodhalí zítra.
- 6.Systém našel k mé práci podobnosti, co to znamená?
Autoři si mohou ověřit, zda nedošlo k použití jejich textu v díle jiného autora.
Co zobrazuje rozhraní vyhledávání podobností a jak jej využít:Podobnost, kterou systém nalezl mezi Vaší prací a prací/pracemi v databázi, nemusí vždy nutně znamenat, že se u jedné z prací jedná o plagiát. Každou práci (podobnost) musí posoudit odborník na dané téma. Neexistuje žádná hodnota %, od které lze práci považovat za plagiát.
1 Procento celkové podobnosti s dokumenty v databázi a zdroji z internetu.
2 Seznam zdrojových dokumentů, se kterými je dokument podobný. U každého je zobrazeno procento podobnosti.
3 U každého zdrojového dokumentu je menu pod ikonou tří teček, kde lze o dokumentu zjistit více informací.
4 Za pomoci křížku lze odstranit z výpočtu zdrojový dokument, který není pro porovnání podobností relevantní (například z něj měl student čerpat a má jej řádně citovaný).
5 Po kliknutí na vybranou zvýrazněnou podobnou pasáž se zobrazí dokumenty, se kterými je text podobný.
6 Číslo v oválu označuje počet dokumentů, se kterými je následující pasáž podobná.
7 Po kliknutí se přehledně zobrazí počty zobrazených, přeskočených i vyřazených dokumentů včetně vysvětlení.
8 Ovály s čísly udržují přehled o zdrojových dokumentech. Přeskočené dokumenty lze zobrazit, vyřazené dokumenty obnovit.
9 Možnost přepnutí na jednobarevnou verzi zobrazení podobností, kdy je míra podobnosti vyjádřena intenzitou barvy.
Soubory uložené v Úschovně nebo Mém webu se zahrnou do vyhledávání podobností pouze v případě, že se jedná o vlastní Úschovnu nebo Můj web. Ostatním uživatelům se podobnosti nalezené v těchto úložištích nezobrazí.
- 7.Systém nenašel dokument na internetu, ze kterého student opisoval
Část podobných dokumentů nepřináší informaci o nové shodě, jen opakující se podobné pasáže zobrazených zdrojových dokumentů. Tyto dokumenty systém přeskočí. Prakticky jde například o rozsáhlejší citace určitého zákona v další stovce závěrečných prací a dokumentů na internetu. Uživatelé tedy nyní neuvidí všechny dokumenty, ve kterých jsou například citovány odstavce z autorského zákona, ale zobrazí se pouze jeden z nich. Ten, který má i nejvíce dalších podobností se zvoleným dokumentem.
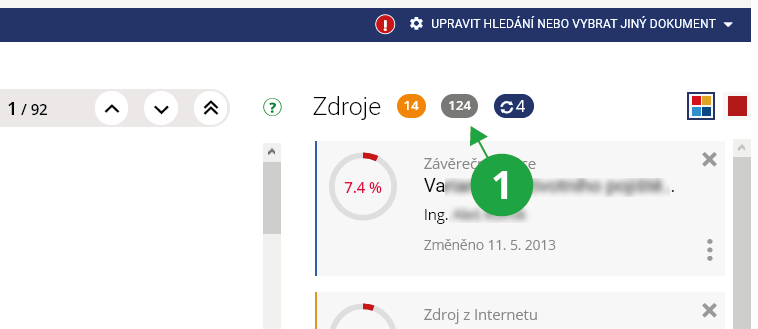
1 Šedý ovál ukazuje počet přeskočených dokumentů, kliknutím na něj se zobrazí seznam těchto dokumentů.
Jako první je potřeba se podívat, jestli se jen nezobrazuje jiný dokument, který danou podobnost obsahuje. Například zda systém neoznačil rovnou sbírku zákonů s textem daného zákona, a nikoliv článek v novinách, který stejný článek komentuje.
K přeskakování dokumentů dochází až v případě, je-li nalezených dokumentů více než 10. Do té doby se dokumenty pro přehlednost ukazují všechny.
Seminární práce v odevzdávárnách a dlouhé odpovědi v odpovědnících jsou kvůli rychlosti zpracování porovnávány primárně pouze vůči sdílené databázi všech zdrojových dokumentů. Je zde tedy rozdíl oproti hledání podobností u závěrečných prací, kde každou závěrečnou práci systém podrobí i přímému zkoumání podobností vůči internetu.
Není třeba se ale obávat, databáze je opravdu rozsáhlá. Ve většině případů tedy už systém „zná“ dostatek zdrojů, ze kterých studenti obvykle čerpají, a také dostatek zdrojů, ze kterých obvykle studenti opisují.
Pokud vyučující zadává seminární práci na velmi aktuální a nové téma a nebo velmi okrajovou problematiku, může se stát, že ji zatím ještě nikdo v závěrečných pracích nereflektoval. Potom sdílená databáze všech zdrojových dokumentů nemusí ještě toto téma pokrývat. V těchto případech lze doporučit, aby učitelé studentům do studijních materiálů do IS PCU nahráli zajímavé, relevantní a hodnotné zdroje pro jejich inspiraci či studium. Zároveň takto budou mít jistotu, že z nich nebudou opisovat.
- 8.Kontrolují se i odpovědi v Odpovědnících?Systém také kontroluje delší texty vepsané jako odpovědi do Odpovědníků. Kontrolují se odpovědi na otázky typu „Vepište text“ (:a) , pokud bylo vepsáno více jak 50 znaků. Tyto odpovědi automaticky systém vkládá do Studijních materiálů předmětu, je-li odpovědník ve studijních materiálech. Pokud odpovědník není ve studijních materiálech, pak se ukládají pod soubor s popisem odpovědníku. Tyto soubory nejsou studentům implicitně dostupné. Pro kontrolu odpovědí v Odpovědnících lze použít:Informační systém Učitel (vybraný předmět) Správa odpovědníku (vybraný odpovědník) odpovědi Kontrola opisování dlouhých textů
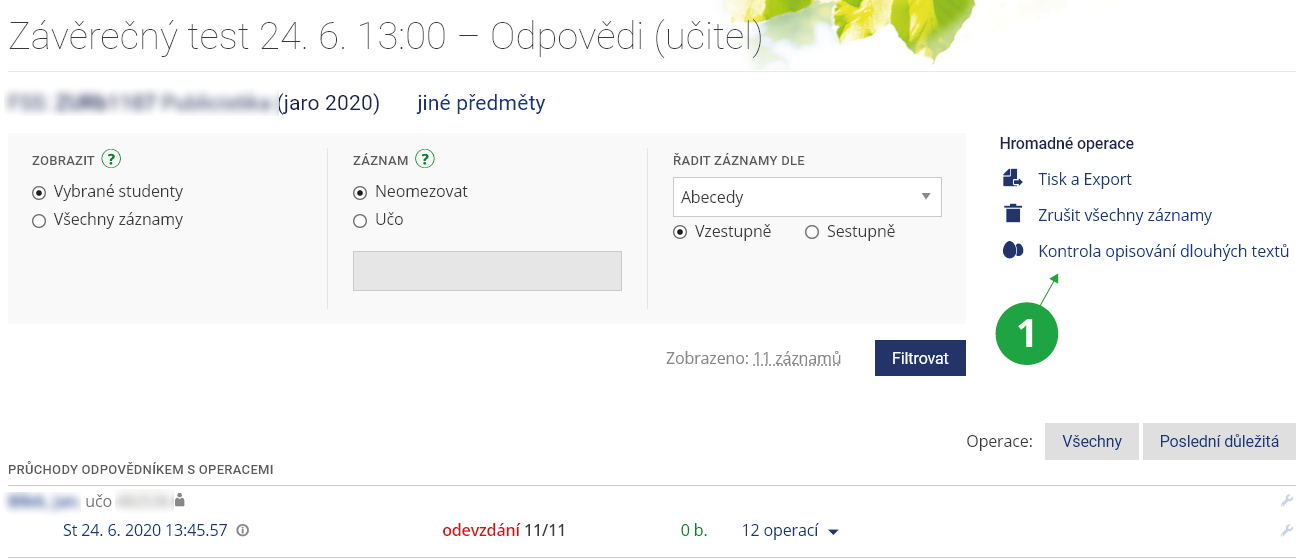
1 Zde je možné zkontrolovat najednou odpovědi v celém odpovědníku.
Zajímá vás, mezi jakými texty se podobnosti v Odpovědnících vyhledávají? Více na toto téma naleznete v otázce Mezi jakými pracemi se podobnosti porovnávají?
Pokud vyučující nechtějí, aby studenti při testu opisovali z jejich prezentací a učebních textů, je možné studentům do studijních materiálů do IS PCU tyto soubory nahrávat. Dostanou se tak do sdílené databáze porovnávaných dokumentů a dlouhé odpovědi v Odpovědnících budou vůči nim porovnávány.
- 9.Jak mohu kontrolovat originalitu prací odevzdaných v Odevzdávárnách?Nástroj pro hledání podobností může pomoci zamezit opisování či znovuodevzdávání prací spolužáků z vyšších ročníků. Pokud od sebe budou studenti vzájemně opisovat, systém vyhodnotí jejich odpovědi jako podobné a zobrazí procento podobnosti. Pro kontrolu prací v odevzdávárně použijte:Informační systém Učitel (vybraný předmět) Odevzdávárny (vybraná odevzdávárna) ikona "podobné jako vejce vejci"
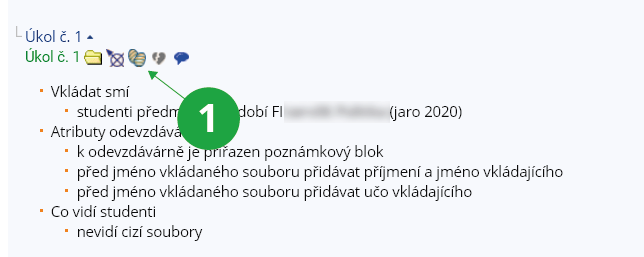
1 Zde je možné zkontrolovat najednou odpovědi v celé odevzdávárně.
Zajímá vás, mezi jakými texty se podobnosti v Odevzdávárnách vyhledávají? Více na toto téma naleznete v otázce Mezi jakými pracemi se podobnosti porovnávají?
Pokud vyučující nechce, aby studenti při testu opisovali z jeho prezentací a učebních textů, je dobré, aby studentům do studijních materiálů do IS PCU tyto soubory nahrávali. Dostanou se tak do sdílené databáze porovnávaných dokumentů a dlouhé odpovědi v Odpovědnících budou vůči nim porovnávány.
- 10.Jak mohu porovnat dva dokumenty mezi sebou?
Pomocí aplikace Porovnej dva, která graficky zobrazuje korelaci mezi podobnými texty v obou dokumentech v místech, kde byly nalezeny podobnosti, včetně míry podobnosti nalezených pasáží.
Aplikace pro porovnání dvou dokumentů.
Aplikace je funkční, i pokud uživatel nemá přístup ke zdrojovému dokumentu. V tomto případě se ze zdrojového dokumentu zobrazí pouze začátky podobných slov, ostatní text je záměrně nečitelný. Toto slouží jako vodítko pro alespoň přibližné posouzení závažnosti textové podobnosti.
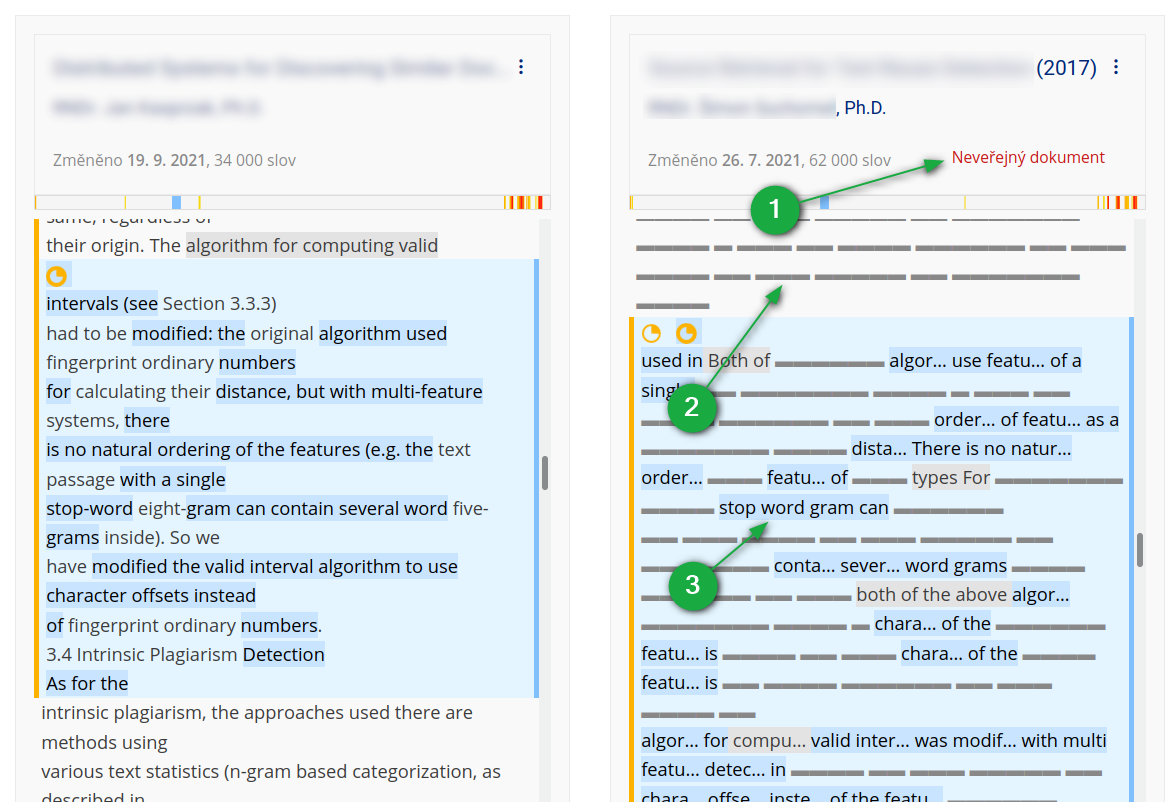
1 Označení neveřejného dokumentu.
2 Nečitelný okolní text.
3 Zobrazení podobných pasáží u neveřejného dokumentu.
Odkaz na aplikaci je dostupný v pravém panelu aplikace pro vyhledání podobností po rozkliknutí tří teček u vybraného dokumentu. V případě, že máte menší obrazovku, je potřeba nejprve rozkliknout panel se zdrojovými dokumenty.
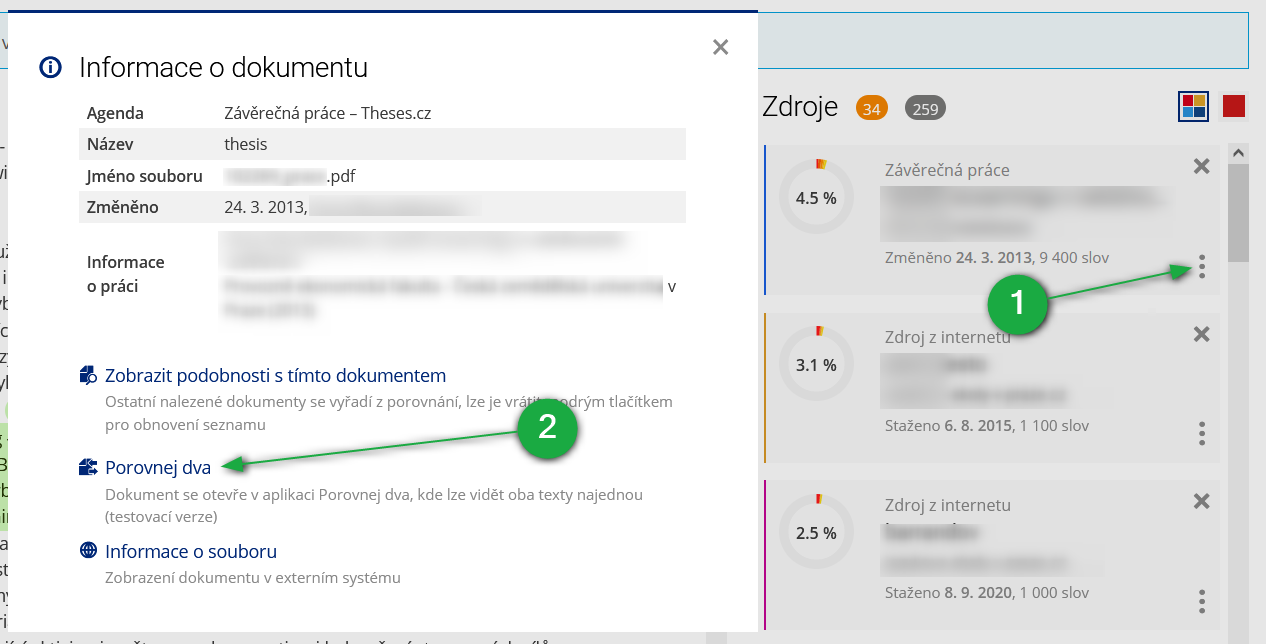
1 U vybraného zdrojového dokumentu klikněte na ikonku tří teček.
2 V zobrazených informacích o dokumentu naleznete odkaz na aplikaci Porovnej dva.
- 11.Jak aplikace Porovnej dva funguje?Aplikace obsahuje řadu grafických prvků, které usnadňují orientaci v nalezených podobnostech. Barvami v různých místech aplikace je značena míra podobnosti pasáže:
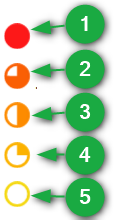
1 Téměř doslovná shoda.
2 Jen mírné odlišnosti.
3 Částečně podobná pasáž.
4 Značně přeformulovaná pasáž.
5 Malá míra podobnosti, řešit jen ve spojitosti s okolními pasážemi.
Doplňkově je míra podobnosti v textu naznačena i vyplněním kolečka.
Porovnávaný i zdrojový dokument je zobrazen podobným způsobem. Text je rozdělen na kratší části, přibližně velikosti odstavce, a prorovnávají se dva po sobě jdoucí odstavce porovnávaného dokumentu se třemi odstavci zdrojového dokumentu.
Na stránce jsou dostupné následující prvky:

- Čas změny dokumentu a počet slov
Pro posouzení, který z dokumentů je starší, případně „významnější“.
- Lineární mapa dokumentu
Zobrazuje výskyt podobných pasáží v dokumentu. V případě že jedno místo dokumentu odpovídá více částem protějšího dokumentu, je použita barva odpovídající největší podobnosti.
- Barevná čára vlevo
Označuje míru podobnosti v konkrétních částech textu.
- Barevná kolečka v textu
Po kliknutí na kolečko se modře zvýrazní příslušná pasáž v obou dokumentech. Na jednom místě může být více koleček, protože jedno místo může být podobné více místům protějšího dokumentu.
- Modře zvýrazněný blok
Vybrané dva odstavce porovnávaného, resp. tři odstavce zdrojového dokumentu jsou podbarveny světle modře a zvýrazněny svislou modrou čárou vpravo.
- Modře podbarvená slova
V rámci vybrané pasáže textu jsou na řádcích výraznější modrou podbarvena slova, která se vyskytují ve vybrané pasáži i v protějším dokumentu. Krátká slova a interpunkce se pro tyto účely neporovnávají, jsou podbarveny podle toho, jestli se vyskytují mezi dvěma společnými slovy.
- Šedě podbarvená slova
Značí slova, která nejsou v obou dokumentech ve vybrané pasáži, ale jsou součástí podobnosti s jinou pasáží protějšího dokumentu.
- Ostatní slova
Nepodbarvená jsou zbývající slova která se v rámci vybrané pasáže vyskytují jen v jednom z dokumentů.
- Čas změny dokumentu a počet slov
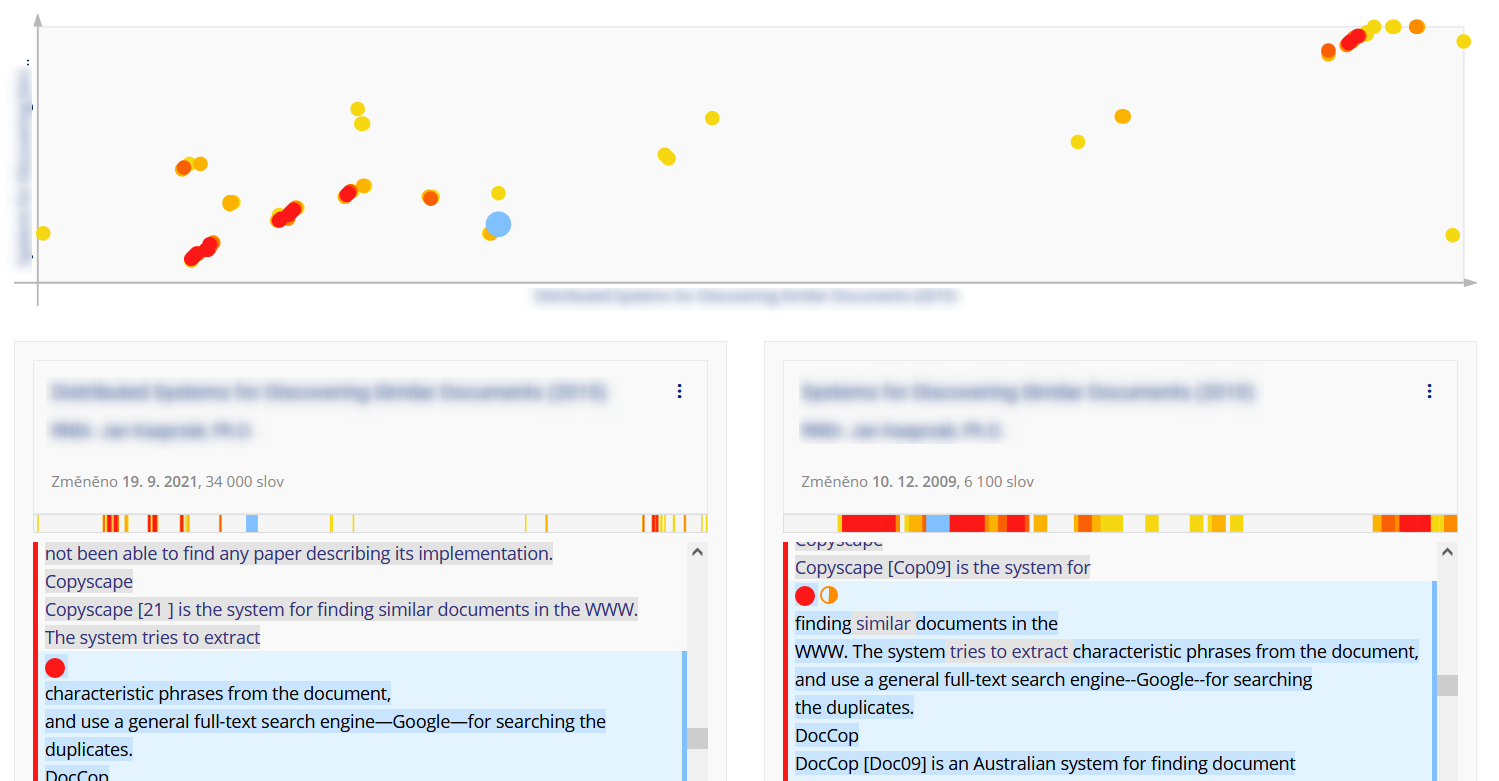
- 12.Porovnej dva: jak číst 2D mapu?
2D mapa ukazuje graficky umístění podobných pasáží v obou dokumentech.
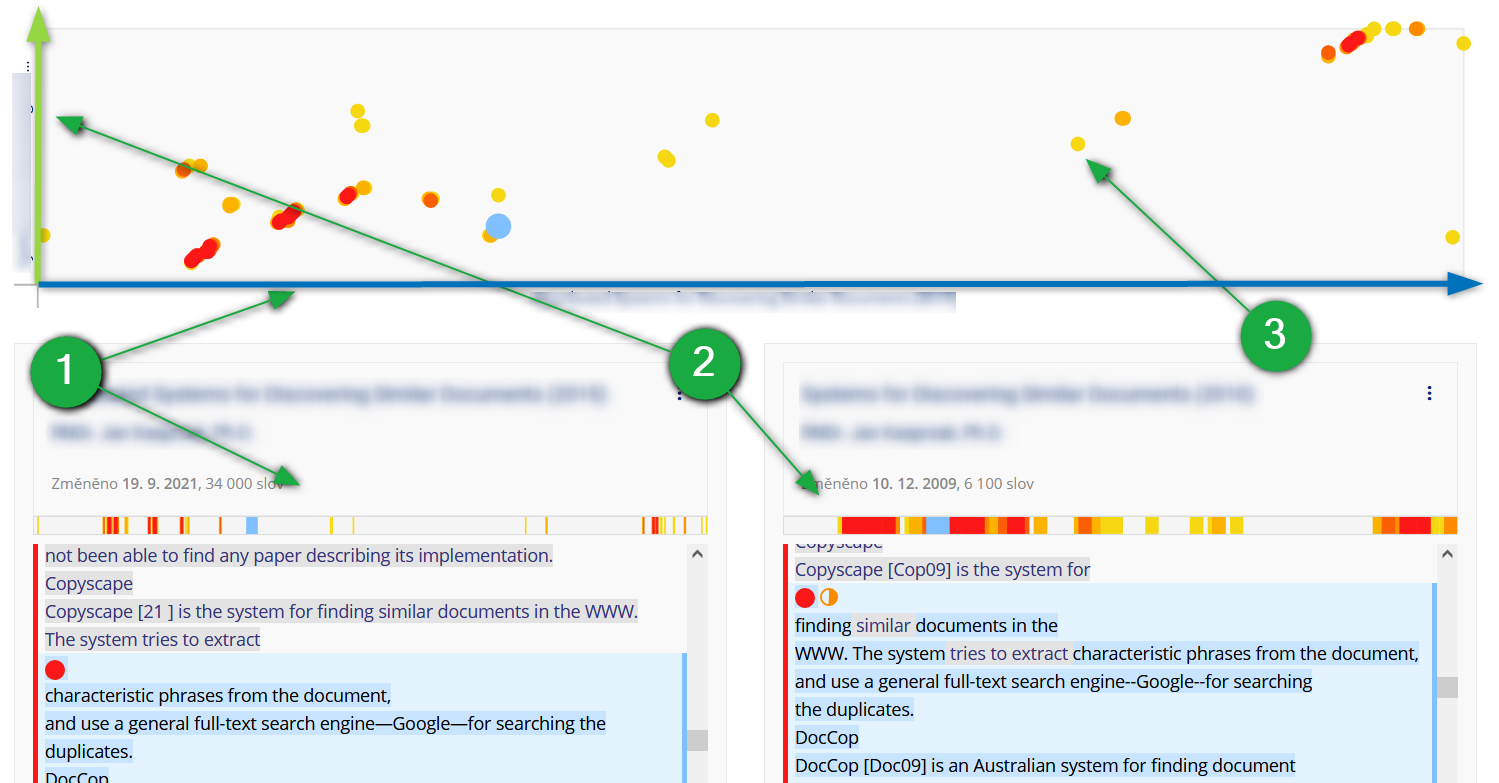
1 Na vodorovné ose je porovnávaný dokument, napsaný zleva doprava.
2 Na svislé ose je zdrojový dokument, napsaný zdola nahoru.
3 Barevné tečky ukazují podobné pasáže obou dokumentů, barva značí míru podobnosti. Kliknutím na barevnou tečku zvýrazníme příslušné pasáže v obou dokumentech.
- Výrazná diagonála
- Výrazná červená diagonála naznačuje rozsáhlý souvislý text vyskytující se v obou dokumentech.

Zde příklad dizertace skládající se z několika článků, přičemž jeden z těchto článků je zde zdrojový dokument. I další podobnosti naznačují delší, v oboru ustálená sousloví, použitá i v dalších článcích, ze kterých se dizertace sestává. Poznámka: sklon diagonály se může lišit podle poměru délek obou dokumentů.
- Úvodní prohlášení autora

Krátká podobnost vlevo dole je typicky úvodní poděkování nebo prohlášení autora, které bývá v rámci jedné instituce standardizované.
- Seznam literatury

Shluk bodů v pravé horní části textu jsou delší sousloví – citace v seznamu literatury. Může naznačovat, že práce vycházejí z podobných zdrojů, ale o plagiát se v tomto případě nejedná. Víceméně diagonální směr naznačuje, že články jsou odkazovány v podobném pořadí, tříděné podle stejného kritéria (např. rok vydání).
- Několik bodů svisle nad sebou
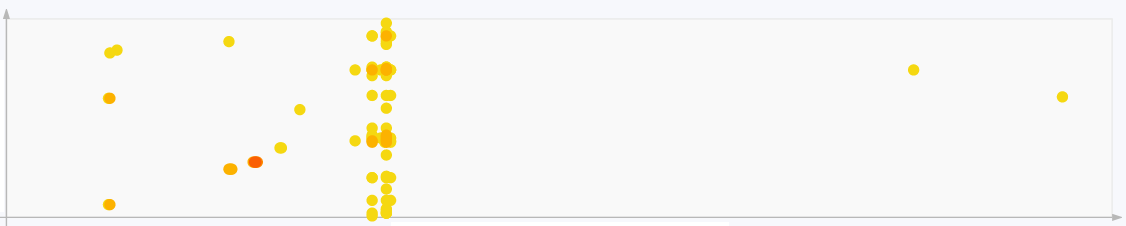
Jedná se o vícenásobný výskyt podobnosti mezi jednou pasáží porovnávaného a více místy zdrojového dokumentu (u několika bodů vodorovně vedle sebe naopak). Typicky jde o delší sousloví, definici nebo jinou formulaci v oboru obvyklou. Zpravidla není třeba řešit.
- Nevýrazná podobnost

Nejde-li o výraznější shluky nebo diagonální linie a jde-li zejména a žlutě nebo světleoranžově zobrazené podobnosti, pravděpodobně se jedná o podobnost v delších ustálených formulacích nebo o společné téma obou textů, obvykle nejde o plagiát.
- Přeformulovaný text

Toto je skutečný plagiát, téměř celá práce napsaná výrazným přeformulováním jiné práce. V mapě se v podstatě nevyskytují červené body, ale zvlněná diagonální linie naznačuje podobnost téměř „od začátku do konce“. Prázdná místa v diagonální linii můžou naznačovat, že systém zde podobnost neodhalil, anebo že zdrojem této části textu je jiný dokument.
Tečky podél horního okraje jsou podobnosti v seznamu literatury, kde zdrojová práce odkazuje literaturu až v závěrečné souvislé části, zatímco zkoumaný dokument odkazuje na literaturu průběžně v místě použití, například poznámkami pod čarou.- Opsaná kapitolka

Toto je stejný dokument jako předchozí, zdrojovým dokumentem je tentokrát článek z Wikipedie. V plagiátu byl použitý jako zdroj se stejnou strukturou informací, ale výrazným přeformulováním a vypuštěním části textu. Vzhledem k výraznému nepoměru velikostí obou dokumentů je zde sklon diagonály téměř svislý. Rozsah zkopírovaného textu jsou necelé dvě strany A4: i takto malými podobnostmi tedy má cenu se zabývat.
- Úvodní část práce

V mnoha oborech je zvykem, že úvodní část závěrečné práce se věnuje přehledu informací v daném oboru. Zde se jedná o dvě maturitní práce přibližně stejné délky ze stejné školy. Tyto práce evidentně čerpaly svojí úvodní část z těch stejných zdrojů (nebo od sebe navzájem). Druhá polovina obou dokumentů (na obrázku pravá, resp. horní) už podobnost neobsahuje, což naznačuje, že druhá polovina dokumentu, text s „vlastní prací“ obou autorů může být originální.
- 13.Co se stane, když budu opisovat?Plagiátorství (opisování, zhotovování napodobenin) je neetická činnost a podvodné jednání, která nemá na vysoké škole svoje místo. Převzetí textu jiného autora bez viditelného označení převzatého textu s uvedením přesné citace zdroje představuje neoprávněný zásah do autorského práva v rozporu s autorským zákonem. Za přestupek hrozí sankce, a to třeba i po ukončení studia.
Nenašli jste odpověď? Pošlete nám svůj dotaz na  fi
fi municz
municz